论文阅读:《Dynamic and adaptive learning for autonomous decision-making in beyond visual range air combat》
本文记录笔者近期阅读的一篇论文所产生的部分记录。
引言
解决的三个问题:
- 把机动和导弹发射决策组合起来
- 论文觉得超视距空战中的对手应该在对抗中不断进化,但是现在提高对手能力的方式都有缺陷,一般不拟真。
- 训练过程中很难选择对手(这是啥意思?原本有很多对手吗?)
主要贡献:
- 动作空间设计上,把机动和火控组合起来
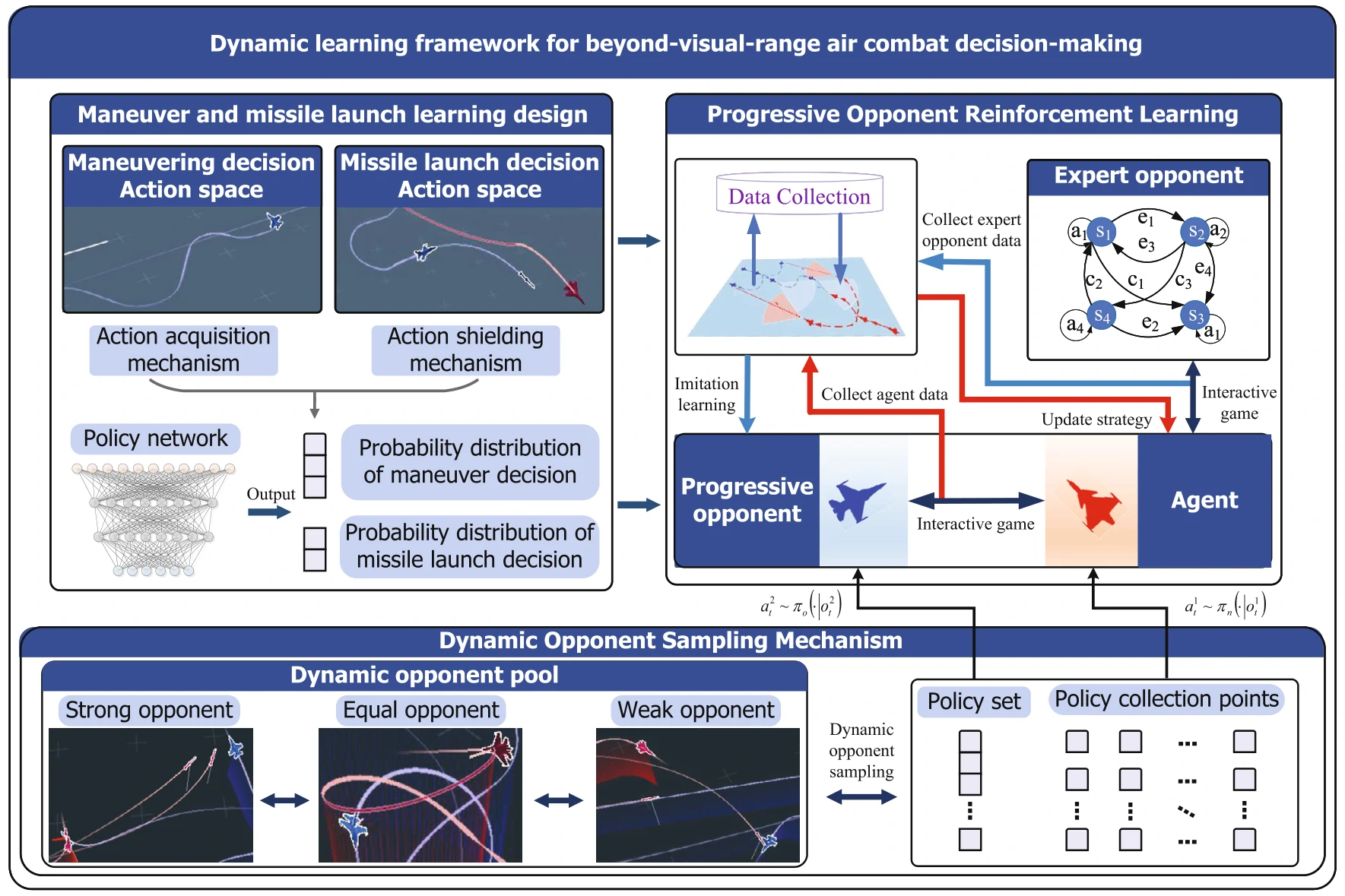
- 提出一种Progressive Opponent RL(PORL),能允许对手的策略也能不断改进
- 提出一种动态选择对手的方式
问题描述
超视距空战设置
典型BVR包括如下阶段:
- 空战开始前就要找合适的位置
- 寻找并追踪目标
- 攻击(发导弹)
- 导弹发射与制导
- 撤退或者继续攻击
angle of attack 超过35度,或者速度在0.25马赫以下,低于30度,那么飞行器可以认为失速;失速超过5秒就失败了。
飞机离敌机100米以内或者离地100米以内,相当于坠毁。
基本机动:直飞、爬升、追踪目标位置、追踪目标角度、把目标控制在三点钟和九点钟范围内、U型机动、蛇形机动。
问题建模
奖励函数
- 存活奖励:胜利+25,失败-25
- 火控奖励:发射导弹+2
- 击中目标奖励:命中+6,未命中-6
- 锁定奖励:锁定敌机+2,未锁定-2
- 制导奖励:导弹锁定敌机+3,否则-3
论文方法介绍
飞行器机动和导弹发射设计
动作分两部分:机动和火控
- 机动:滚转、过载、油门
- 火控:0或1
动作掩码:默认1110,火控禁止
- 导弹有关的掩码:导弹冷却中 or 目标距离过远 or 雷达未锁定目标,禁止发射;
- 机动有关的掩码:被导弹锁定,禁止高风险机动;进入自我防御状态时,强制逃离机动0100,油门不足,禁止高耗能机动,
策略网络的输出:输出各个动作的概率分布,输出导弹发射的概率。
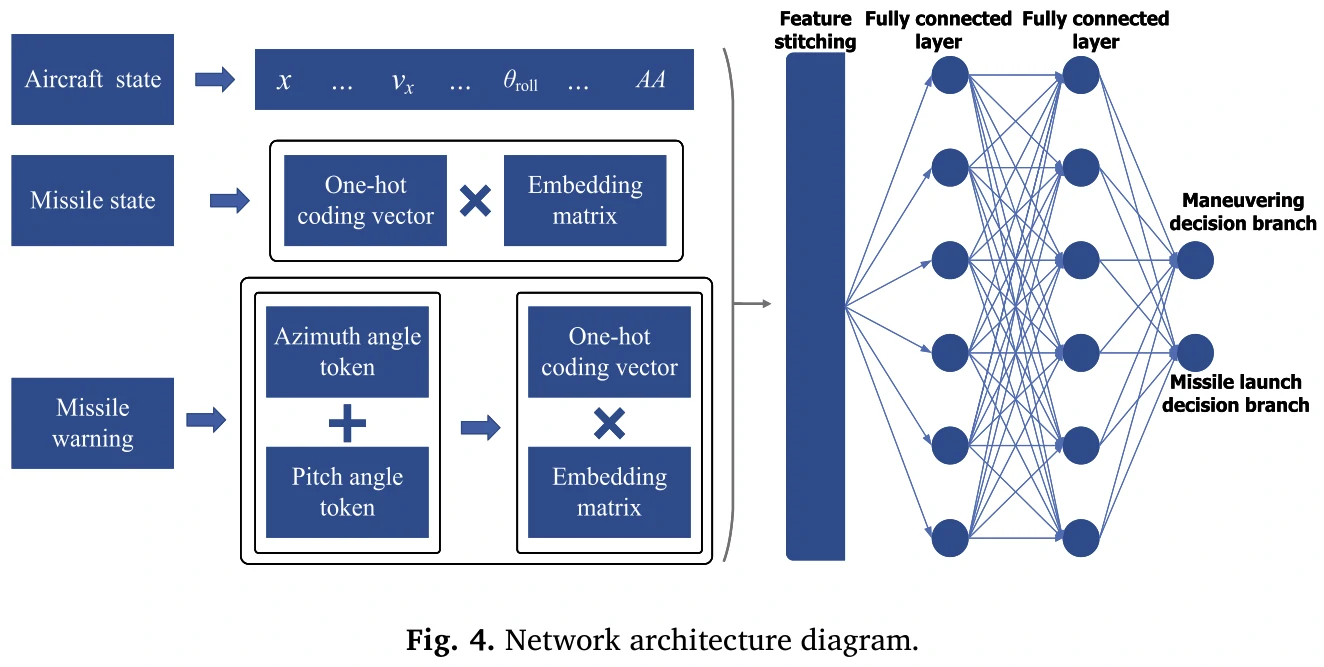
- 状态输入层:位置、速度、高度、相对距离、LOS、ATA、AA、其他参数
导弹状态嵌入:one-hot编码,0未发射,1已经发射,2命中,3发射失败
- 冗余设计:没有的导弹状态会用3来填
导弹预警嵌入
- 冗余设计:无效的警告标记为t=0
特征拼接与隐藏层:拼接上述一些状态
全连接层
分叉输出层
机动:先输出每个动作的分数,再用softmax变成概率分布的样子
导弹的掩码:如果没有锁定目标或者导弹在冷却,就强制为0
两个回放缓冲池:一个机动,一个导弹
Progressive Opponent Reinforcement Learning (PORL)
结合了自博弈、模仿学习和对手建模的有关知识。
主要实现过程:
- 创建智能体、专家对手、逐渐变强的对手
- 数据收集:让智能体和专家对手对抗,收集状态动作奖励数据
- 用收集的数据去训练一个逐渐变强的对手,通过模仿学习来让策略覆盖那些专家对手
- 让智能体的对手在专家对手和不断变强的对手交替,打专家时学最优策略,打其他对手时在低风险环境下巩固策略
- 策略更新:每局结束时根据游戏结果更新策略。
专家对手的构建
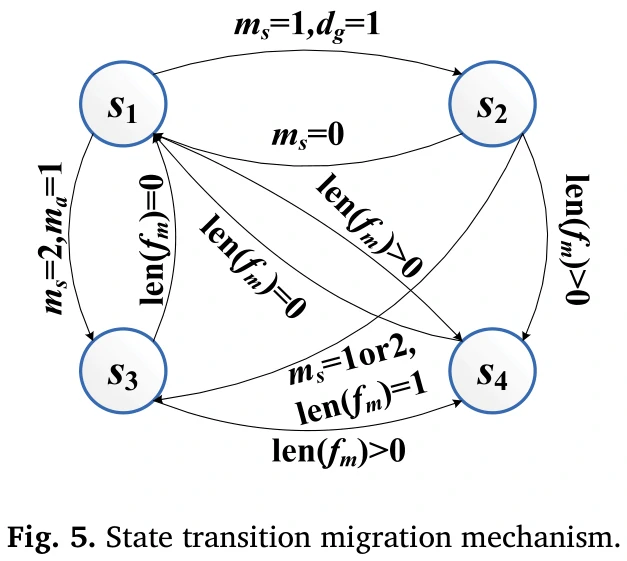
状态:追踪目标、导弹制导、机动、自我防御
状态之间的转换看表2和图5

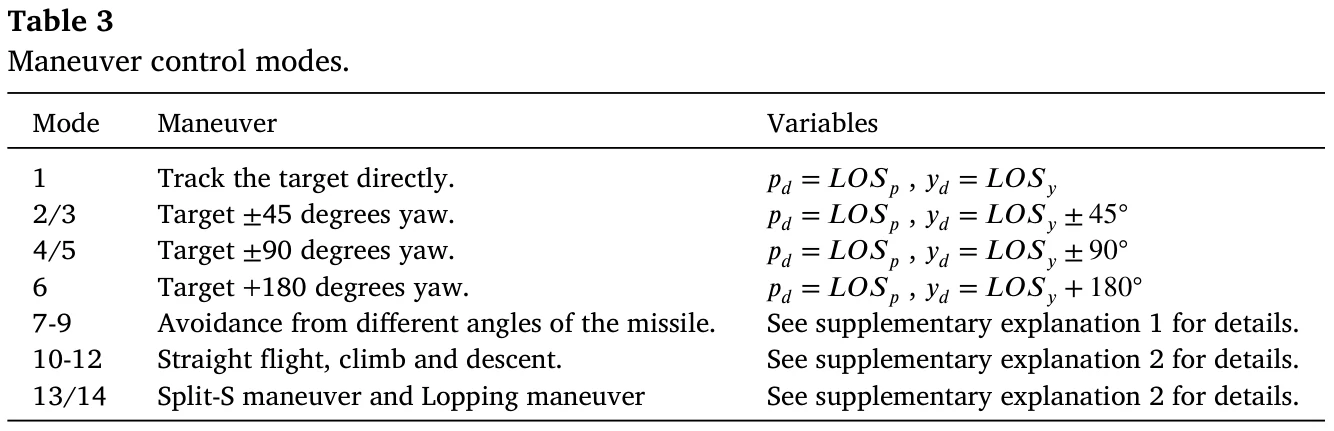
具体一点的机动:看表3
逐步增强的对手的构建
- 策略更新函数看公式15
- 大致上用SAC算法
动态的对手采样方式
- 根据智能体和对手在过去对局的胜率,把对手分类为强的、中等的和弱的
- 接下来很多公式全是在讨论怎么计算胜率、怎么构建指标给对手分类的
- 对手池随着训练过程不断更新

超视距空战下的决策仿真模拟实验
环境
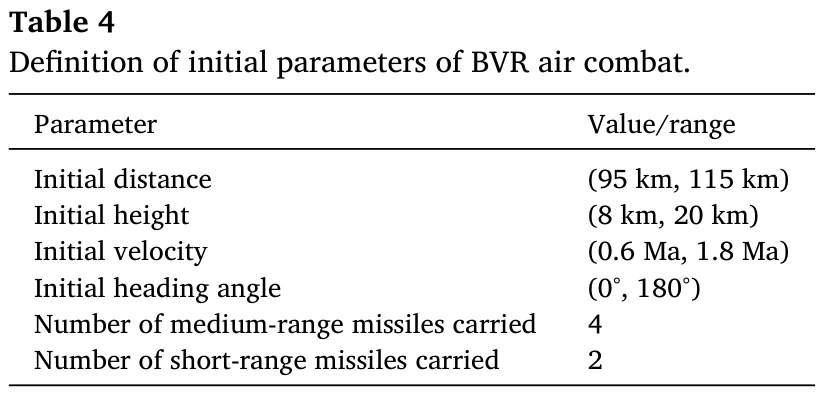
初始参数见表4。
超参数:discount rate is 0.9, buffer capacity is 1×10^5, soft update coefficient is 0.05, learning rate is 3e-4, network structure is [256, 256], activation function is ReLU, and batch size is 256.
对手的学习方法的对比分析
- 用来评估分析PORL(POL)方法的表现
- 对比包括自博弈学习和模仿学习
- 让POL和自博弈学习(SGL)和模仿学习(IL)
对比图看图6。
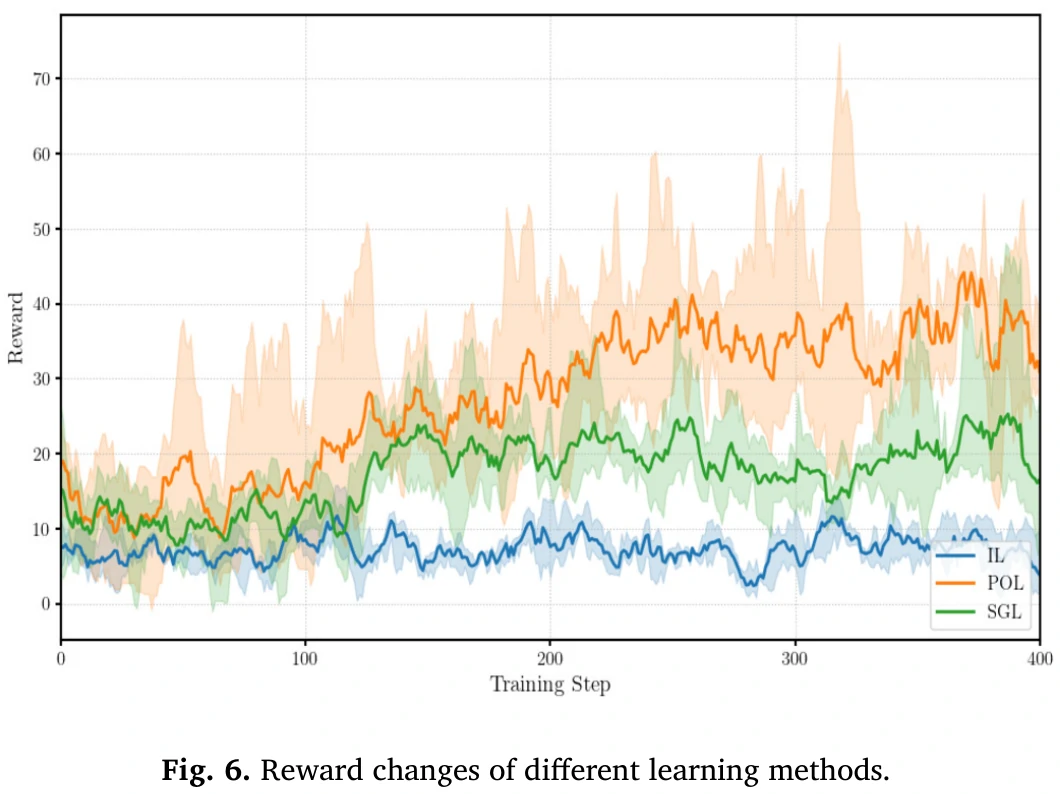
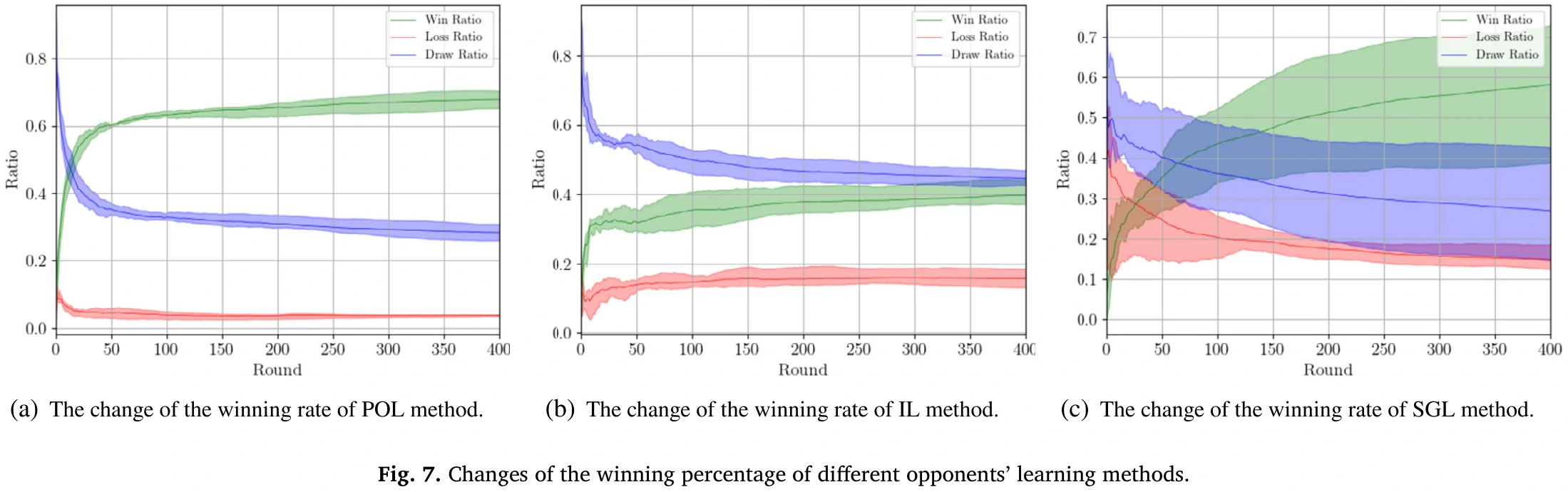
分析:
- 模仿学习提供更强的专家对手,奖励少;
- 自博弈学习强调逐步上升的奖励趋势,但奖励比起论文方法不稳定。
胜率变化图看图7。
不同智能体学习的方法对比看图8和表6。
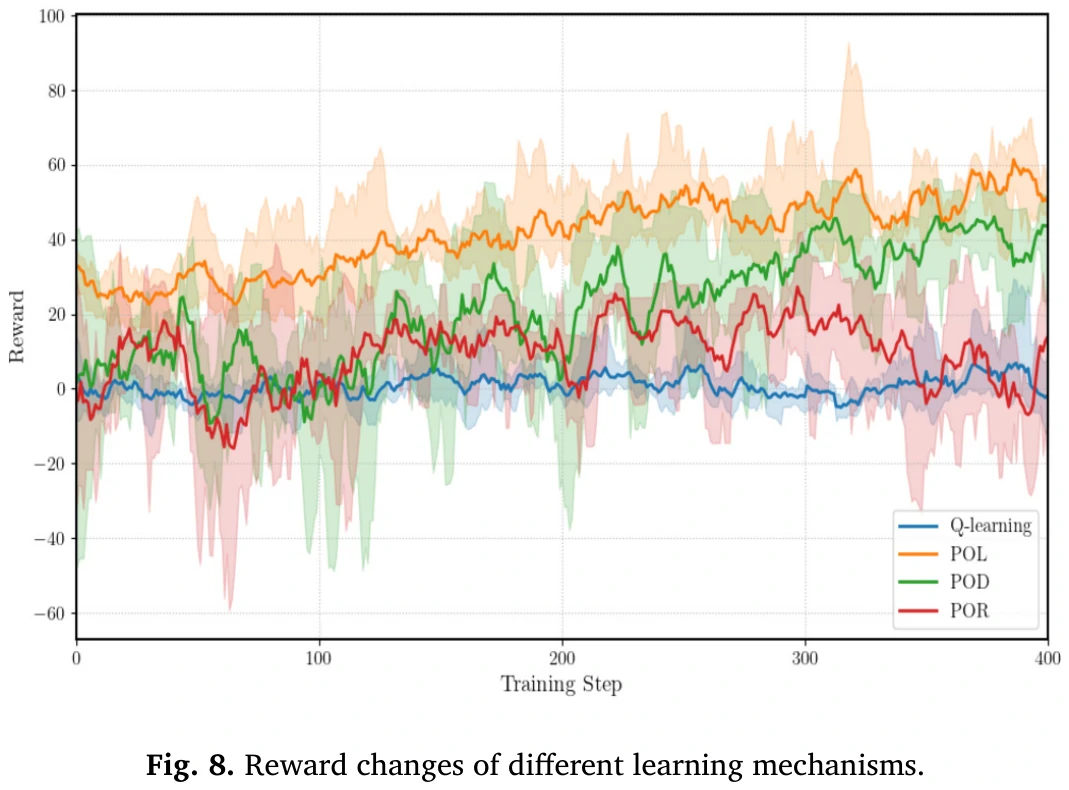
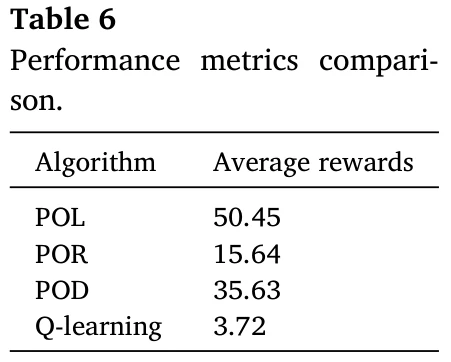
POL是论文方法,POR在其基础上加一个随机,POD把估计和更新智能体策略的算法改成DQN,Q-Learning不用说了。
对手采样方式的对比分析
从固定对手里挑选对手,来更好地评估采样方法的性能(控制变量)。
三种对手,有不同的能力,看表7。
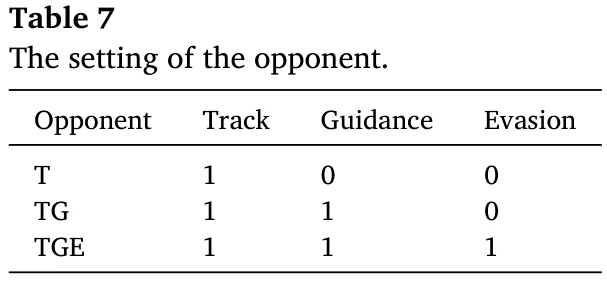
T:track,追踪能力;G:Guidance,导弹制导能力;E:Evasion,规避攻击的能力。
智能体和三种对手对抗,看图9和10。
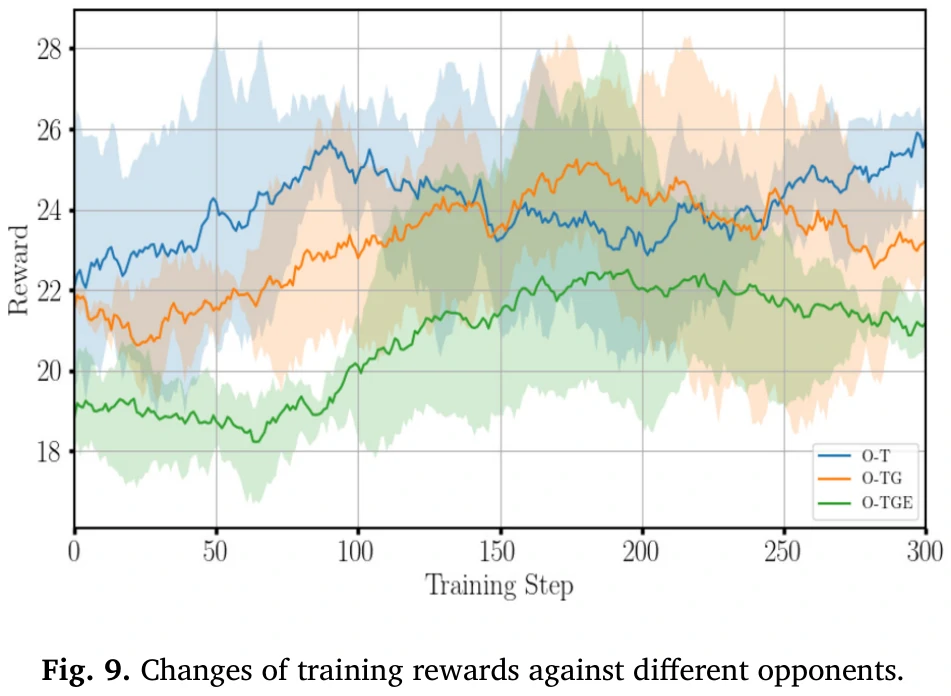
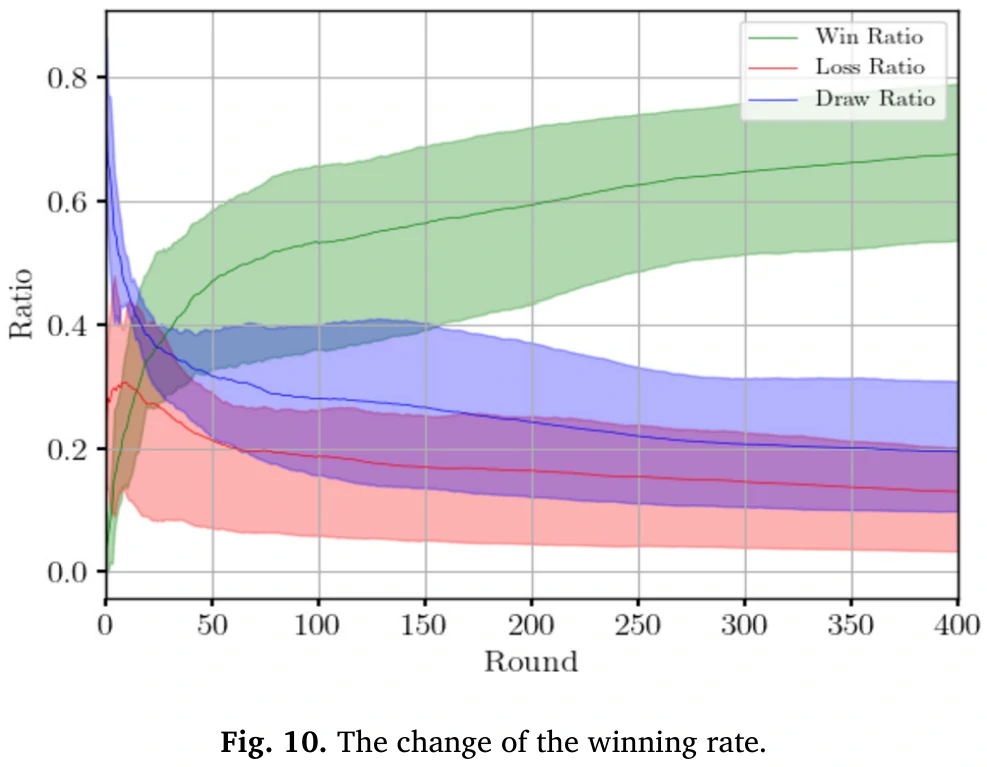
图9中打TGE的奖励总体最低,能看出对手的强度对训练影响较大。
通过对表7中三种对手的训练,最终得到三种不同的策略,然后对这三种策略进行泛化检验,每一种策略与所有对手的策略依次对抗1000局,并计算胜率。具体统计结果如图11所示。
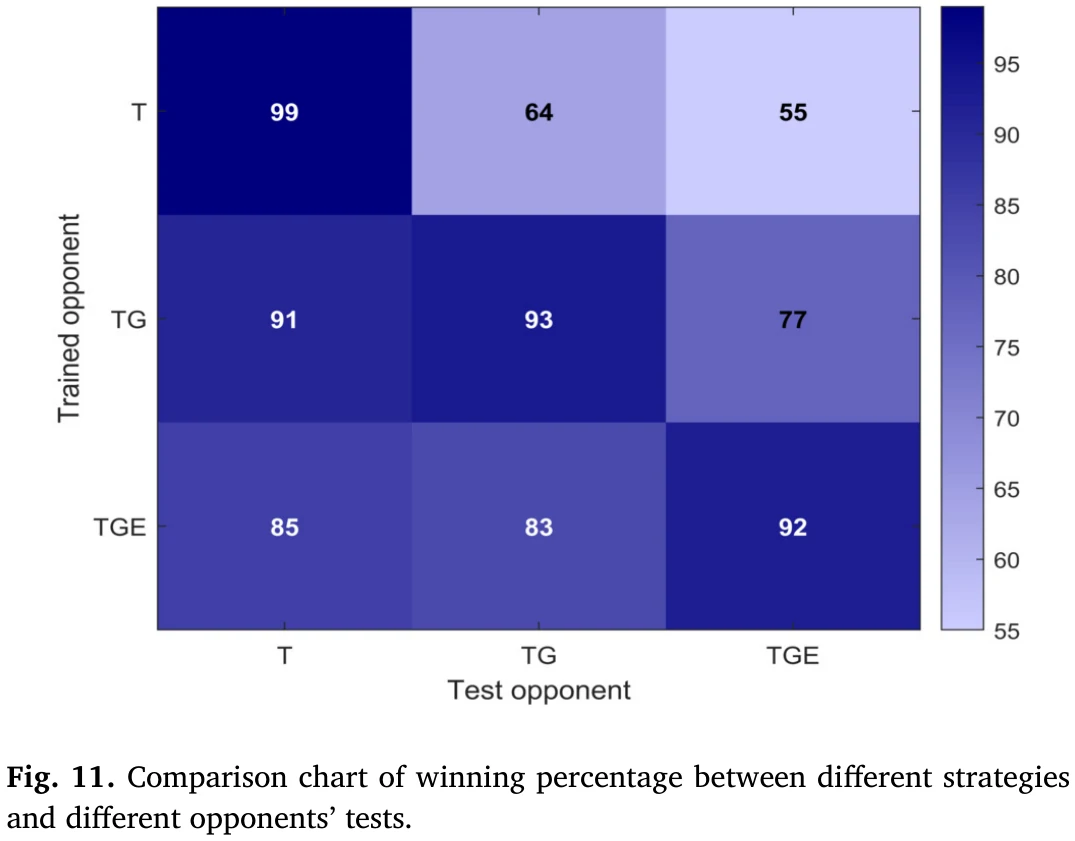
横轴:对手在测试过程中的策略,纵轴:针对不同对手策略训练得到的三种策略。
由图11可以看出,针对TGE和TG对手训练的策略在对抗所有对手策略的对抗测试中保持了较好的平均胜率,具有较好的泛化性,而针对T对手训练的策略在对抗所有对手策略的对抗测试中平均胜率较低,这进一步说明针对强对手训练的策略可以更好地击败弱对手。
此外,还可以看出,经过训练的策略在面对相同对手策略时的胜率高于面对其他不同对手策略时的胜率,这也说明了,如果只打一种对手,就容易过拟合。
接下来是不同对手采样方法之间的对比:
- IOSM:本文方法
- WPSM:基于胜率选对手
- RUSM:随机选
结果看图12
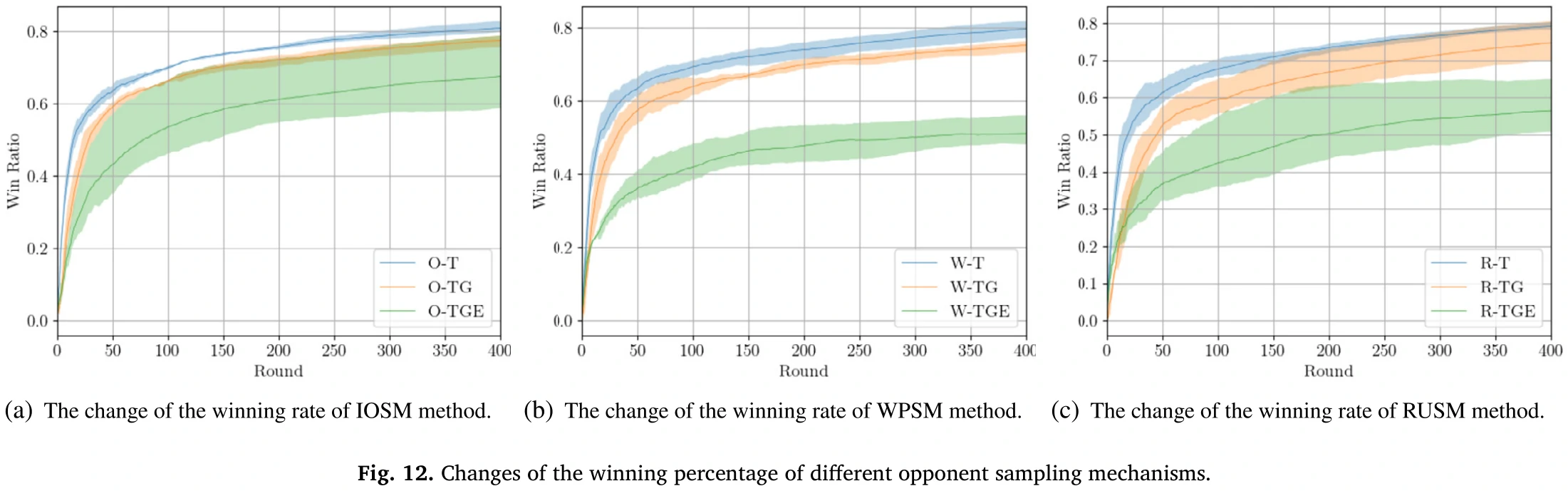
图13:不同采样机制下,智能体对抗不同对手的熵的变化情况。
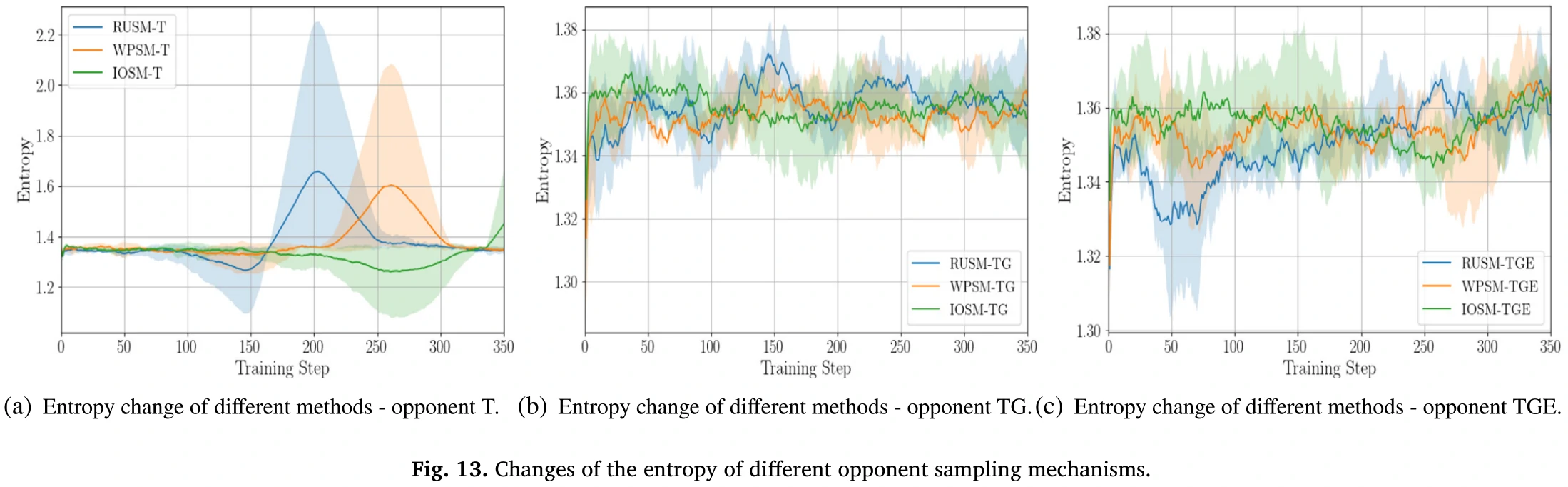
- 面对比较强的对手时,熵的波动更加剧烈。
- 面对TGE对手(最强的对手),论文方法和WPSM的熵变化都比较平稳。
为了测试泛化能力,再把用不同采样方法训练出来的模型和表7里的所有对手对抗,再额外加2种对手:OM和ON,这两种对手策略在对手策略TGE的基础上细化了攻击与机动规避的研究组合,两者的对抗难度更大。
对每个对手的策略进行500回合的对策测试,并计算胜率(评价指标I)和成本-效果比(评价指标II:即消耗的导弹数量与击败的对手数量之比,数值越小越好)。
详细信息如表8所示。
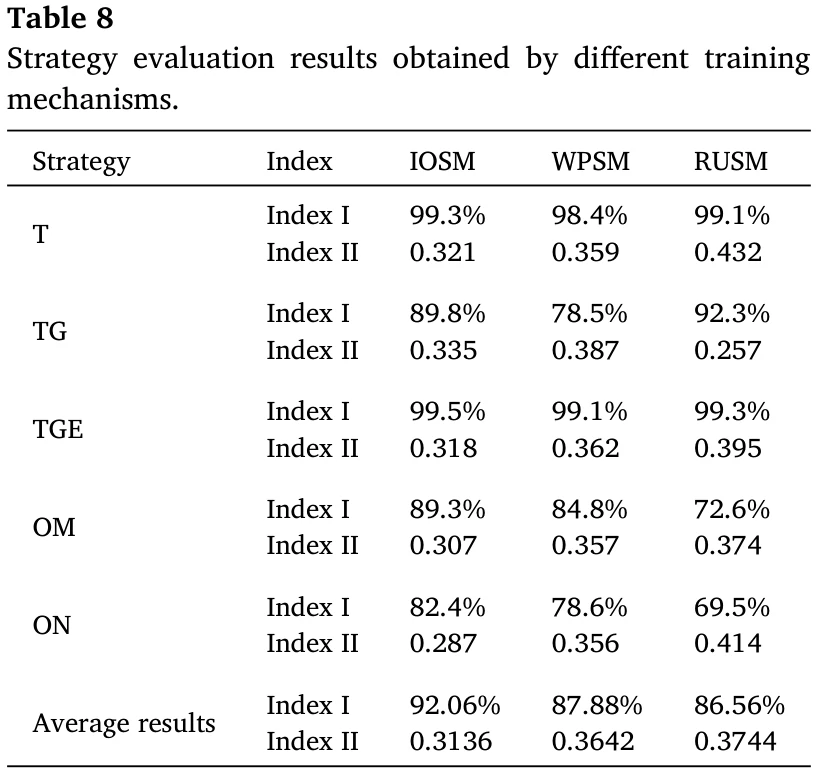
从表8看出论文方法比用于对比的方法胜率更高;打之前没见过的OM和ON对手,胜率也比其他两种方法更高,说明泛化能力强。
用训练后策略进行对抗的模拟分析
红方用论文方法,蓝方代表训练过程中遇到的对手?
看图14-16。


如图14所示,红方和蓝方之间的超视距空战模拟的初始情况如下:双方相距105千米,初始接近速度为1.5马赫,且机头方向相反。此时,红方和蓝方都需要迅速寻找对方,并迅速占据有利位置,以有效对抗并压制对方。
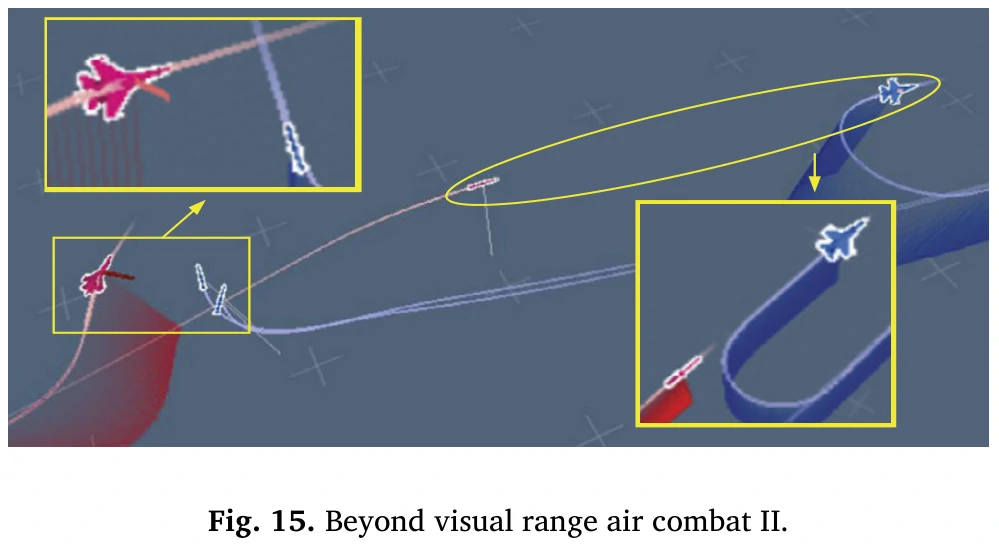
然后图15和图16以及文中对它们的描述全部是在谈论红色方是如何通过比蓝机更好的机动来取得优势位置,最终发射导弹击溃地方赢下来的。
(如图15所示,当红方和蓝方接近时,双方同时发射导弹。此时,红方更好地计算了迎面而来的导弹的规避角度和距离,并在接近状态下进行了侧向机动。这使得红方能够有效地避开导弹威胁,同时最大限度地减少机头方向的变化。相比之下,蓝方在较远的距离处执行了掉头动作。尽管它成功避开了导弹威胁,但过度改变了机头方向,使尾部暴露给了红方。随后,如图16所示,红方成功抓住了蓝方的尾部,并在高度和角度上取得了显著优势。在这一-阶段,蓝色方已经来不及调整飞机方向以形成攻击角度了。最终,红色方成功在蓝色方之前发射了导弹,实现了决定性的交锋并将其击溃。)
这之后再把对局距离缩短到55千米,看图17-19。
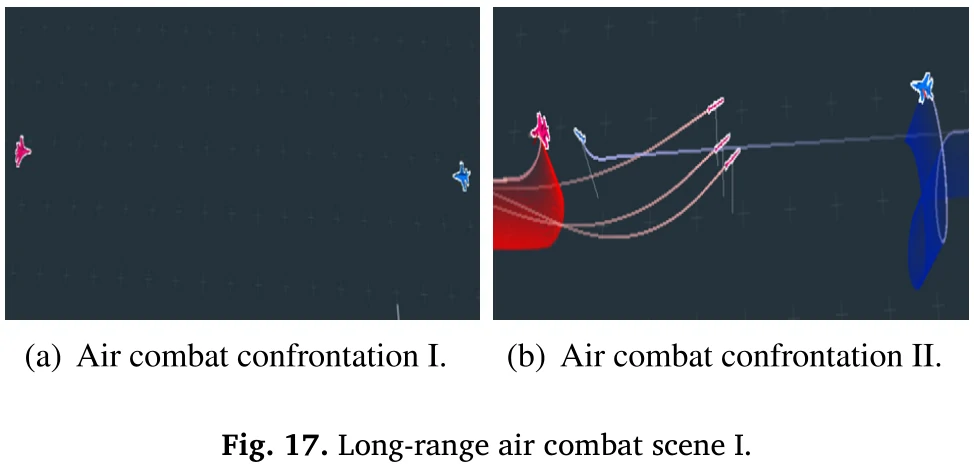
详细描述了一顿之后,最后结果是蓝方赢了,论文说这个蓝方也是用论文方法训练的,所以也能体现论文方法的有效性。
评价
因为能力欠缺+看的时间有点短,所以不确定合理性有多高。
论文结构上:一上来就明确说了论文想解决哪几个问题,然后对每一个问题都有提出对应的解决方法(创新点),像论文里面有三个问题,就是三个创新点,其中第一个是动作空间的设计,估计是不好做对比实验,所以论文没做,主要还是针对后面两个创新点设计的实验。
章节也是按照突出创新点的方式划分的,像奖励函数在论文里不是创新点,它就放在第二章,占了一个很小的篇幅,然后动作空间和训练算法是重点,就放在第三章里面细讲。
能看出整篇论文为了证明论文方法的合理性,进行了大量的实验,对实验结果的描述篇幅占了很大的比重每一个方面都有至少2种实验,至少能充分体现工作量。
动作方面,这个有关把机动和火控组合在一起的动作设计,正好在611那边训练模型的时候也在做,所以可以做个参考。火控掩码感觉在611那边有一定的可行性,至少能起到一点作用。
老板和前辈意见:
这论文其实不一定做了多少实质性的创新,甚至有些图或者实验的真实性有斟酌空间,比如图6的这个实验,打IL训练出的对手,一开始奖励就很高,而且奖励值在训练过程中都没怎么提升,有点说不过去。但是论文写的很完整详细,这种给人家评审,人家都不好意思reject。可见真正创新和写论文发论文还是有一定的区别的,写论文有写论文的技巧,像论文行文结构这些就可以借鉴学习一下。